
Updated May 2023 (We update this article every year)
Machine learning and AI have been strong selling points for cloud vendors for years, and the LLM and generative AI boom we’re experiencing today has only made it an even more significant differentiator for cloud platforms. This may be why both AWS and GCP are doubling down and putting even more effort into developing their ML platforms: SageMaker and Vertex AI. These platforms were launched only a few years ago, but since then, they have continuously evolved and expanded, adding so many new features that it’s almost impossible to track the new releases announced by each.
So how can you choose between the two? In this blog post, I’ll take you through the major fundamental differences looking at AWS’s SageMaker vs. GCP’s Vertex AI to hopefully assist you in making this strategic decision. Here are a few of the crucial points, in my opinion, to consider when evaluating the platforms.
More posts in this series:
Don’t choose based on what’s currently available
As of 2023, comparing AI platforms can be challenging due to the paradigm shift in the form of AI solutions such as ChatGPT and Dall-E2. Consequently, potential users may often read that one platform supersedes the other due to some killer feature, only to find out a few weeks later that the other has been secretly working on its own version. These gaps get closed regularly. Adding to this, as organizations mature their ML practices and roadmaps over time, a requirement that may have seemed crucial when choosing the platform is no longer important. This is why I DON’T think that generating a “grocery list” of SageMaker and Vertex AI features should be key when evaluating your ML platform, especially when this decision will affect your organization for the long haul.
Having said that, it’s a good idea to look at these two blog posts by Alex Chung and Vineet Jaiswal, who did an excellent service to us all by listing and comparing the features of each platform. They make it easy to see that both platforms are very capable, with many overlapping features that will allow you to do just about everything on either platform. And if there is a missing feature nowadays? Just wait a few months for the other platform to catch up.
Proprietary AI models
Although not included in this comparison, OpenAI has proven that proprietary machine learning models are becoming a significant part of AI platforms. These models are trained on vast amounts of data and require advanced research to generate. Alphabet, the parent company of Google Cloud, has been gathering user data through popular applications such as Gmail and Google Search. Furthermore, Google’s acquisition of companies like DeepMind has further strengthened its position in AI research, making them better equipped to offer advanced AI APIs. Google has already introduced its own models, like Bard and PaLM, as part of its offering, solidifying its position in the market. On the other hand, AWS had to seek 3rd party assistance from AI21 Labs, indicating a lack of in-house AI capabilities. AWS appears to be more focused on infrastructure rather than AI-as-a-service solutions. Therefore, while all players are still in the early stages of the race, I believe Vertex AI is the more promising contender in this domain.
Machine learning needs data
The second point in which I feel that there is a difference between Vertex AI and SageMaker is actually not officially a part of either platform. Machine learning and AI require good data infrastructure, and in this criteria, Google Cloud seems to come on top. Google’s data offering has more advanced tools, and they integrate well with Vertex AI and BigQuery, one of the leading data warehouses out there. On the other hand, AWS customers that I meet often seek data solutions outside of the native AWS ecosystem, like Databricks or Snowflake. This difference is more apparent in tabular data use cases and not necessarily in dense data cases like images, videos, or audio. Therefore, for organizations and individuals that need an out-of-the-box data platform, GCP has an edge.
Serving models in production
Practicing ML in different organizations can take many shapes and forms. While some organizations may focus more on research or training models, others focus on building production-grade ML-integrated applications. Even though model hosting only serves a small part of the entire ML pipeline, SageMaker’s hosting solution gives an advantage to organizations that need to manage their models in production. This was one of the early features of the platform and seems to have been well planned out from the get-go. SageMaker implements DevOps best practices such as canary rollout, connection to the centralized monitoring system (CloudWatch), deployment configuration, and more. SageMaker also offers cost-efficient hosting solutions such as Elastic Inference, Serverless Inference, and multimodal endpoints.
In comparison to AWS, GCP has some drawbacks when it comes to deployment. Firstly, the separation between deployment and deployment configuration is not as clear, and there is no management of serving templates that can be used across different deployments. Secondly, the service does not support scaling to zero, which can result in higher costs for low-usage deployments. Another issue is that the maximum payload size for online inference is limited to 1.5MB, making it challenging to work with larger images or other media types. Additionally, the native support for different algorithms is more limited.
Ease of use

I acknowledge that this paragraph will probably be the most controversial in my comparison since user experience is hard to measure, especially between two different platforms with some parts that don’t even overlap. However, here I found GCP to have a clear advantage over AWS.
Despite all the advances made in machine learning tools over the past few years, ML is still hard to implement, especially at production-grade quality. Adding to this ongoing shortage in ML and MLOps engineering talents, a platform’s user experience becomes an amplifier for team productivity. And let us offer some examples:
- GCP resource views are global. It’s not important in which region the Notebook instance is running. Vertex AI has only one page, showing all the Workbench (Jupyter Notebook) servers. I can only imagine how uncomfortable it is for a user to find out that they accidentally launched an expensive GPU server in a godforsaken region and did not shut it down for days.
- SageMaker notebooks are not accessible via SSH. As strange as it may sound, the notebook instances cannot be remotely SSHed into. This doesn’t allow comfortable usage like remote code execution with an IDE.
- SageMaker notebook instance types and VPCs cannot be changed after launch. Additionally, when shutting down a notebook, the libraries that were installed during the run are lost and need to be reinstalled. The Python environments that SageMaker offers are also not helping; often, users encounter numerous conflicts when trying to install or upgrade popular Python libraries.
- SageMaker studio – a fork of Jupyter Lab that AWS extended to be a full ML dashboard has, in my opinion, become too complicated. The studio is supposed to be a management tool; however, you basically need to launch it because it’s running on a server instead of it being serverless or maybe just a part of the AWS console.
I have some more examples, but you probably get the message – GCP is more intuitive to use, in my opinion, saving your developers expensive time.
Pricing

Price is, of course, one of the most important considerations when choosing your ML platform, but comparing it can be very tricky. Why? Because it’s almost impossible to compare apples to oranges. Apart from the machine itself, each platform offers different cost optimization products (Savings Plans, CUDs). The performance itself can change based on features that aren’t related to the machine directly, like network and so forth. Nevertheless, we did sample 4 typical use cases:
- Notebook server with a low-spec machine.
- Training with CPU-balanced machine.
- Inference with a high-spec CPU machine.
- Notebook with a V100 GPU.
All pricing refers to the main US regions: AWS Ohio and GCP us-central-1.
The results were a bit surprising:
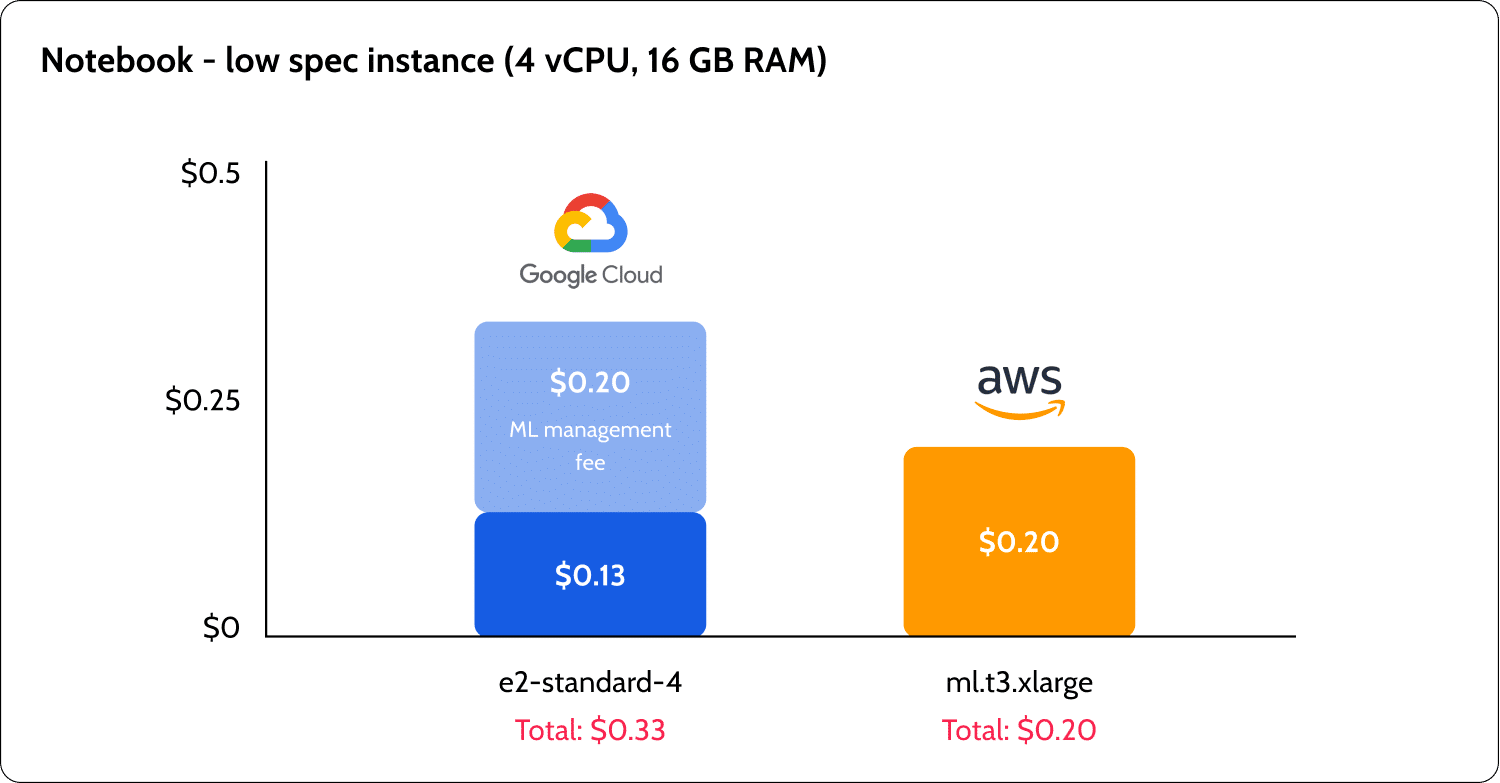
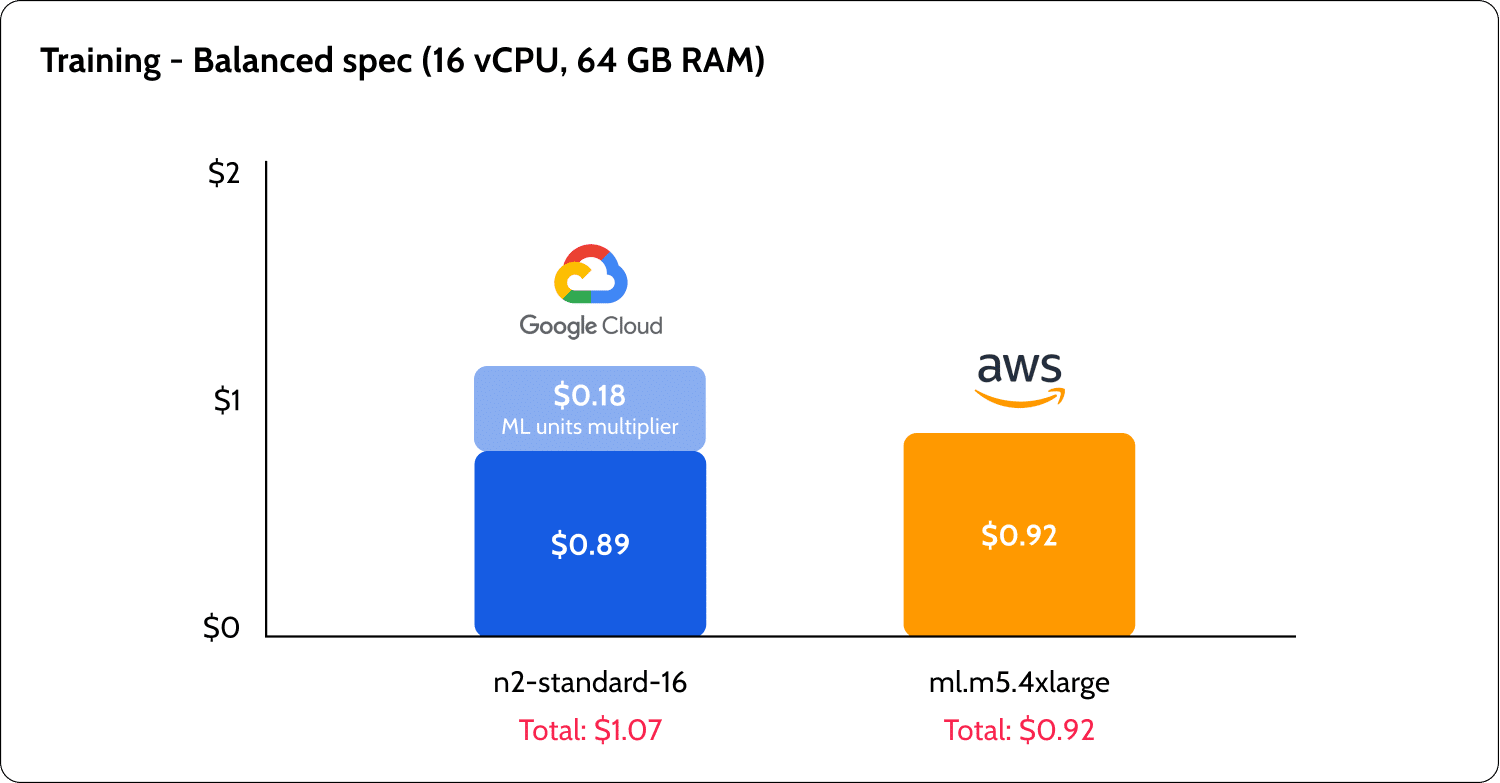
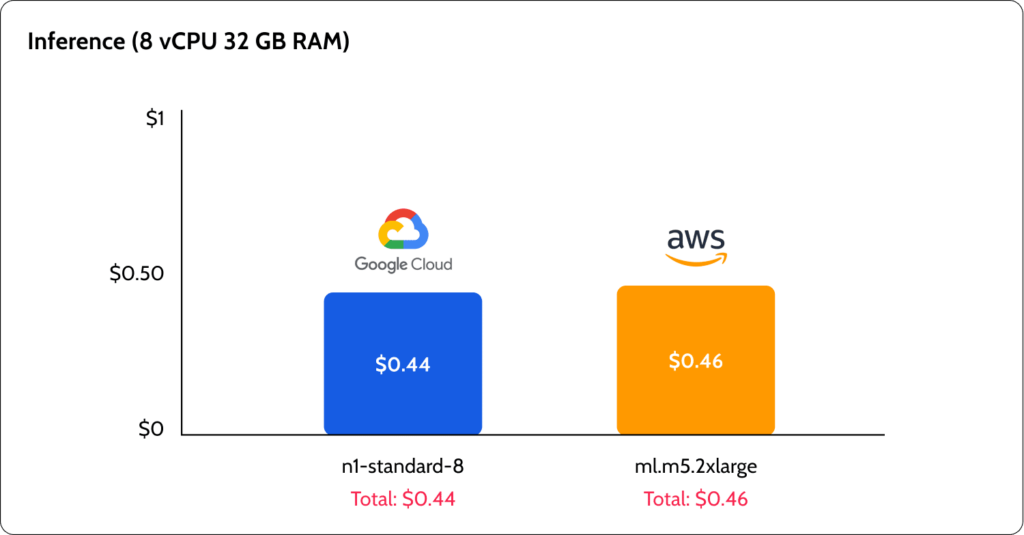
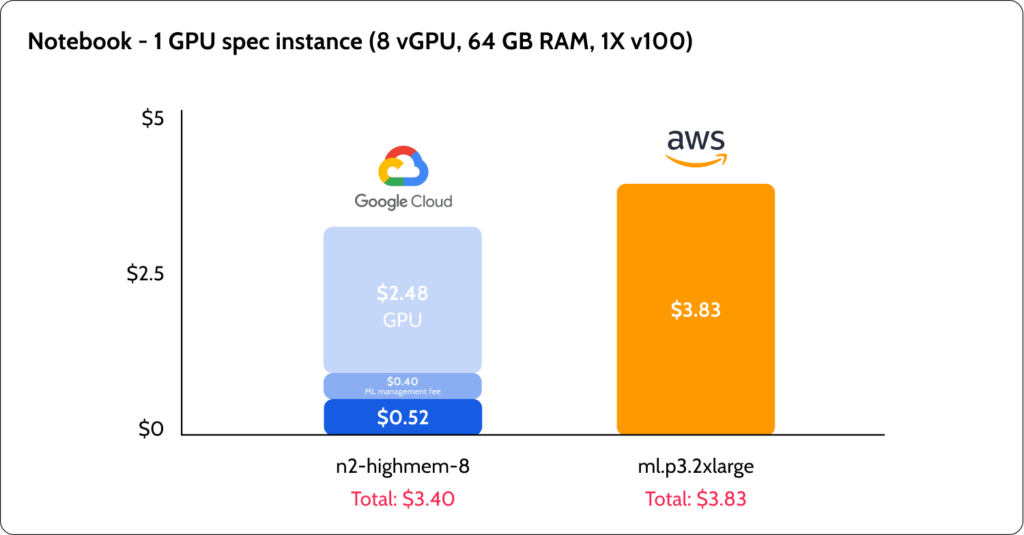
There were major differences between GCP and AWS, not only in the prices but also in the way that they are structured. AWS seems to offer better low-spec pricing with their t3 burst instances that can be good for running notebooks for experiments. GCP offered a lower cost for inference and GPU instances. However, the GCP pricing was very complicated to understand.
Pricing structure
AWS simplified the process of ML services pricing by creating machine types with the “ml” prefix. AWS users know that p3.2xlarge, for example, is an 8×61 machine with Tesla V100, with the “ml” prefix; users can find the equivalent of using this machine with the SageMaker system. GCP, on the other hand, complicated the pricing. For example, model training pricing is based on Consumed ML Units – besides a note saying that this number is based on the hardware used and the time it was used, I couldn’t find a clear explanation of how many Consumed ML Units would 1-hour training be translated to for all cases. Additionally, I had to scan many pages of pricing to come up with the cost of a Jupyter Notebook server.
Different hardware offering
One thing that GCP had done better was the ability to generate custom combinations of GPU / CPU. With GCP, it’s possible to change the GPU/CPU ratio; therefore, if I want a machine with more CPUs, it doesn’t mean that I have to use more GPUs as well.
Additionally, GCP and AWS both have unique hardware offerings. GCP offers the Google-branded TPUs – specifically designed for deep learning tasks and are compatible mainly with TensorFlow – these machines can drive down costs for high throughput computations. AWS offers Elastic Inference – which gives users access to a fraction of GPU, letting them pay less for sparse usage.
Best of breed or best of suite?
While both platforms offer a vast set of tools as part of their suite, just like any other cloud platform – it’s never complete. In many cases, cloud users may need to turn to 3rd party tools to complete their native cloud spec. PagerDuty for alerting, DataDog for monitoring, or Snowflake for data warehousing.
This holds true for ML monitoring as well and is largely influenced by the maturity of the organization’s ML and MLOps activities. As organizations mature and scale in their use of ML, simplified ML monitoring may no longer be sufficient to ensure the health of their models in production. The domain of ML monitoring is usually split into two parts: data monitoring and model monitoring. And while these two concepts are crucial for the health of deployed ML applications, the offering of both cloud platforms will often send you on to a 3rd party tool such as Superwise.
Model monitoring
AWS and GCP both present an approach that is closer to endpoint monitoring rather than ML model monitoring. The two platforms essentially offer a way to create a monitoring job that tracks one of the ML endpoints that’s deployed to them. However, when monitoring ML models’ performance, it’s not necessary to couple between an endpoint and the monitoring job. All that SageMaker and Vertex AI had to do was develop a service that runs over the ground truth, predictions, and timestamps. SageMaker is indeed doing so, but they are not providing clear enough documentation on how to monitor models that are deployed outside of the ecosystem. GCP is even more lagging. AWS, however, does allow you to configure an endpoint to save its calls to S3 quite easily, allowing you to integrate external ML monitoring tools with some minor effort involved.
Data Monitoring
GCP based its data monitoring solution on the popular TFX open-source library. Allowing users to leverage the tool, including its UI, to evaluate data drifts, feature skews, and more. AWS uses its own library called deequ, which is less popular but demonstrates similar capabilities. Both platforms still don’t seem to have a good architecture for this solution, making the capabilities for data monitoring limited. In my humble opinion, AWS wins some more points here for their solution because it allows better integrations with the monitoring processes.
So, which platform should I choose?
First, you need to remember that choosing an ML platform is also a question of choosing a cloud vendor, and to this, there are many more points that we didn’t cover, like Kubernetes, support, cost credits, stability of the infrastructure, and more. Both have many advantages, and they both keep expanding their capabilities. The major differences that I found can be summarized as follows: GCP feels easier to use, while AWS seems more ready to take to production.
Secondly, it’s important to note that although it’s beneficial to stay updated on the advancements of each platform, it seems that neither of the two can fully meet all the requirements of an ML platform. For instance, the limited model monitoring offering highlights that integration with third-party services (as commonly done with other cloud use cases that are not ML) will remain a necessity for these systems. Therefore, if you select an ML platform and it doesn’t provide everything you require, you should mind how easy the integration with other PaaS and SaaS solutions will be.
Ready to get started with Superwise?
Head over to the Superwise platform and get started with easy, customizable, scalable, and secure model observability for free with our community edition.
Prefer a demo?
Request a demo here and our team will show what Superwise can do for your ML and business.
Everything you need to know about AI direct to your inbox
Superwise Newsletter
Superwise needs the contact information you provide to us to contact you about our products and services. You may unsubscribe from these communications at any time. For information on how to unsubscribe, as well as our privacy practices and commitment to protecting your privacy, please review our privacy policy.


