
Model observability has been all the rage in 2021, and with good reason. Applied machine learning is crossing the technology chasm, and for more and more companies, ML is becoming a core technology driving daily business decisions. Now that ML is front and center, in production, and business-critical, the need for model monitoring and observability is both plain and pressing. Practitioners across the board agree that ML is so fundamentally different from traditional code that models need a new breed of monitoring and observability solutions. All of this is true, but model observability can be so much more than the sum of its parts when adopted together with a production-first mindset.
This article will explore what a modern model monitoring and observability solution should look like and how a production-first mindset can help your team proactively exploit opportunities that model observability presents.
A new breed of observability
Before we dive into monitoring vs. observability, let’s take a second to talk about what it is about ML that requires a different approach. Ville Tuulos and Hugo Bowne-Anderson recently published a great article on why data makes MLOps so different from DevOps. Simply put, models aren’t linear; they are infinitely more immense, more complex, more volatile, and more individualistic than their traditional software counterparts. They operate at scale, both in terms of input complexity and input volume, and are exposed to constantly changing real-world data. So how do we effectively monitor and observe a system that we cannot model ourselves? Applications with no overarching truths like CPUs where even the ground truths (if we know them at all) are subject to change? Processes where a ‘good’ result can be relative, temporal, or even irrelevant?
This is the true challenge of model observability. It’s not about visualizing drifts and or building dashboards. That just results in data scientists and ML engineers babysitting their monitoring and literally looking for needles in the haystack. Model observability is about building a bigger picture context, so you can express what you want to know without defining minute details of each and every question and model.
The road to autonomous model observability
Model observability is paramount to the success of ML in production and our ability to scale ML operations. Still, just like ML, it is both a high-scale solution and a problem. The first step we need to take to achieve observability is to open the black box and get granular visibility into model behaviors. The ability to see everything down to the last detail is valuable, but it’s not practical at scale. At scale, you don’t have the capacity to look at everything all the time. It’s about automatically showing you what’s important, when it matters, why it’s an issue, what should be done, and who needs to do it.
Autonomous model observability must do a specific set of things to justify its claim to fame.
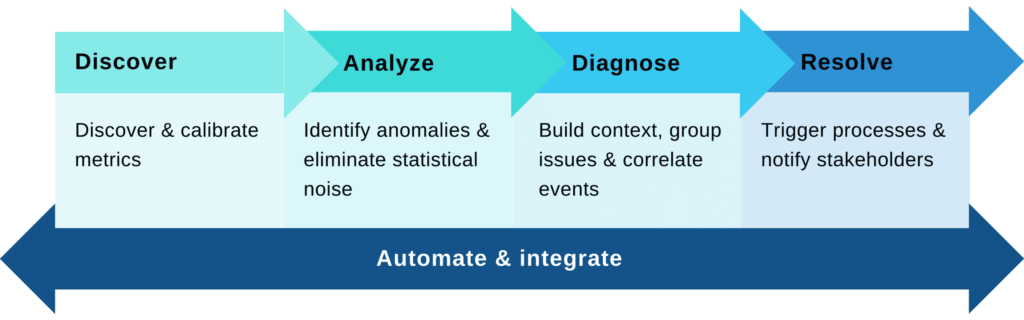
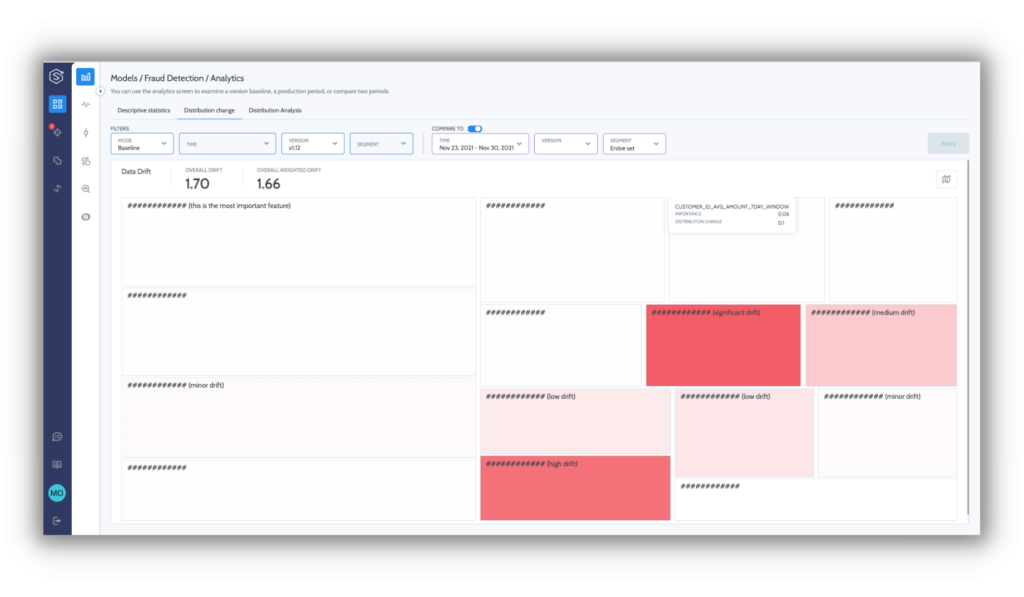
Step 1 is about creating visibility into the black box and discovering the set of metrics pertinent to a model and calibrating their scale. This visibility reflects all the different elements in the process, such as:
- Inputs and pipeline health: tracking the drift levels of our inputs to ensure the model is still relevant and validating the health and quality of the incoming data.
- Model decision-making stability: how robust is our ML decision-making process? For example, a model now rejects 40% of loan requests relative to the 20% it usually rejects. Is a specific feature now abnormally affecting the decision-making process?
- Process quality: measuring the performance of the process, usually in supervised cases, based on the collected ground truth. Such performance metrics can be as simple as precision/recall or complex and even customized to cases. For example, normalized F1 score based on the level of the transaction amount or identifying weak spots that the model is not well optimized for.
- Operational aspects: are there traffic variations? Are there changes in the population mix/composition? Is our label collection process stable?
All of the above should be accessible and visible across versions and on the segment level, as many cases occur for a specific sub-population and won’t be apparent on an aggregated view.
Step 2 is all about zeroing in on signals and eliminating noise by adapting to seasonality and subpopulation behaviors to surface abnormal behaviors. As domain experts, you are the ones that know what types of abnormalities are interesting (e.g., model shift on the subpopulation level), but it’s impossible to manually express them with single, static thresholds that take into consideration the seasonality and temporality of the process.
Step 3 is about identifying risks and streamlining troubleshooting with grouped issues and correlated events to build context for faster root-cause analysis. Correlation isn’t causation, but it’s an excellent place to start analyzing and troubleshooting issues. For example, let’s take an ML process based on multiple data sources exhibiting a pipe issue with a single source. In this case, we’ll probably see an issue/shift in all the features that were engineered based on this source. As that is correlated, it should be displayed together as there’s a strong indication that the underlying data is the root cause.
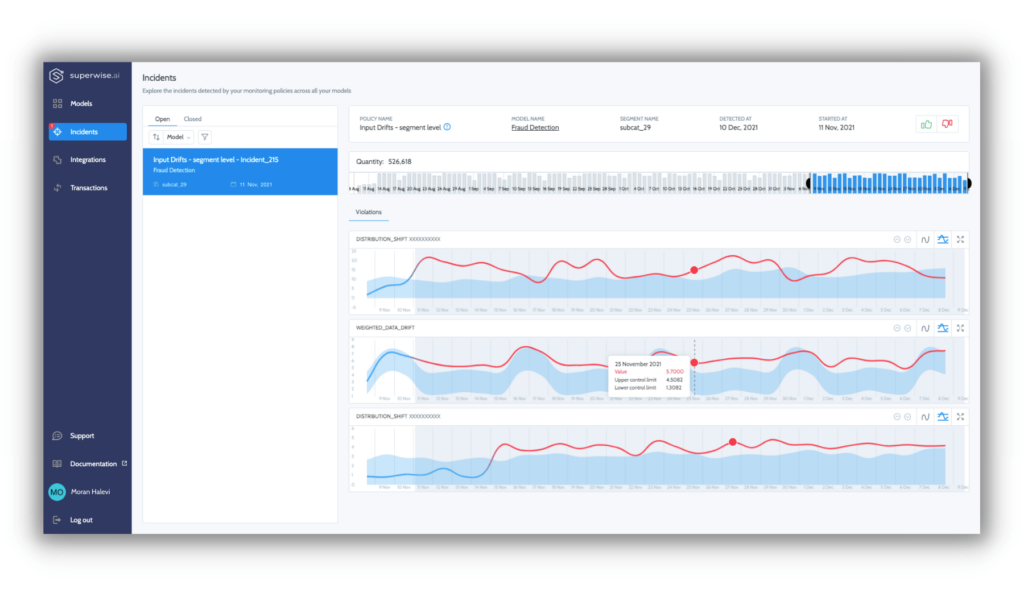
A positive side effect of the context built by grouping correlated events is that it further reduces noise.
Step 4 (the monitoring part) is about taking action and letting you abstractly express business, data, and engineering failure scenarios and how stakeholders should be notified. ML is multidisciplinary, and for different issues, different teams, singularly or in collaboration, will own the resolution. With that in mind, not only is it critical that teams get alerts promptly with all of the in-context information they will need to take corrective action before issues impact business operations, but it’s also critical that the right teams get the right alerts; otherwise, your stakeholders will suffer from alert fatigue. Automating this process is vital to successfully embed the monitoring aspect of model observability within the existing processes of each team.
In addition to all this, autonomous also means giving organizations the freedom to consume observability as they see fit. This goes beyond the self-governing aspects of model observability that discovers metrics and builds contexts. It is about enabling open platform accessibility that lets businesses holistically internalize model observability within their processes, existing serving platforms, and tools. With an open platform, it’s easy to connect and consume each step via APIs. That empowers the organization, builds ML trust, and enables higher-level customizations specific to each organization.
Production-first model observability
Model observability has the potential to be much more than a reactive measure to detect and resolve issues when models misbehave, and it’s the shift to a production-first mindset that holds the key to achieving these benefits. With production-first model observability, every decision to improve a model is supported by production evidence and data. It helps us validate that a model is creating ROI for the organization and ensure that everything we do, be it deploying a new version or adding features, increases ROI and the quality of our business. Production-first model observability completely disrupts the research lead mindset that had dictated data science and machine learning engineering for so long and opens the door to continuous model improvement.
Retraining is only the first and most obvious of continuous improvements. Many other continuous model improvement opportunities can be leveraged, such as A/B testing, shadow releases, multi-tenancy, hyperparameter tuning, and the list goes on. Production-first empowers us to answer our operational ML questions with our data instead of general rules of thumb and best practices.
- On what data should we retrain? Is fresh is best true? As ML practitioners, we shouldn’t be leveraging historical assumptions – we can analyze and retrain proactively based on prediction behavior.
- What subpopulations is our model not optimized for? Or protect subpopulations that are prone to bias?
- How do we improve our existing model? Should we add features/ data sources? Should we adopt a different algorithmic approach? Should we eliminate non-attributing features and reduce model complexity?
Production-first model observability exposes continuous improvement opportunities, which means shorter paths to production, robust deployments, faster time to value, and the ability to increase scale.
Want to see what autonomous model observability looks like?
Request a demo
Everything you need to know about AI direct to your inbox
Superwise Newsletter
Superwise needs the contact information you provide to us to contact you about our products and services. You may unsubscribe from these communications at any time. For information on how to unsubscribe, as well as our privacy practices and commitment to protecting your privacy, please review our privacy policy.


