Our previous post on understanding ML monitoring debt discussed how monitoring models can seem deceptively straightforward. It’s not as simple as it may appear and, in fact, can become quite complex in terms of process and technology. If you’ve got one or two models, you can probably handle the monitoring on your own fairly easily—and decide whether you should build or buy a tool. But once you scale your ML models in production, you may discover that you’ve inadvertently gotten yourself into a bad case of ML monitoring debt. This post offers some words of wisdom and just plain practical advice on identifying and dealing with this debt.
How do you know if you’re in debt?
Your monitoring tool can’t accommodate new use cases
Different use cases require different performance metrics, monitoring strategies, and dashboards. Over the years, we’ve seen a number of experienced companies hit a wall when their use cases expanded. They started out with simple, in-house monitoring but turned to us when their custom tool couldn’t generalize for new use cases. The situation goes downhill fast when each team builds its own monitoring capabilities instead of having a centralized monitoring platform that can accommodate all the different–and future–use cases.
You’re firefighting issues your monitoring didn’t catch
The inherent challenge with monitoring machine learning is that ML makes predictions. Even if you have all the correct measurements in place, there’s no way to know for sure whether the algorithm is performing well unless your use case has ground truth feedback. Then you can know if the predictions are either right or wrong.
It’s not enough to simply measure your model’s performance. You need to be able to detect these uncertain situations where the algorithm makes predictions but has a high probability of getting them wrong, which means you also have to measure the data quality, level of drift, and more. Hunting down abnormal drift or data quality issues is tricky. And it’s something you can’t easily configure in advance. When it’s time to scale up your operation, you need to measure the entire process and go beyond it by ensuring you have advanced anomaly detection or trend detection capabilities. This way, you can more quickly understand when and where things go wrong in different models.
You are drowning in alerts
Getting just the right amount of alerts is a delicate balancing act whenever you do any kind of monitoring. To few alerts can mean you miss important problems, but too many alerts can also mean you’ll miss incidents because they get lost in the overload. Regarding model and data monitoring, we are essentially monitoring a stochastic process usually applied at high dimensionality and large scale. This makes the predicament even more complex because it’s tough to define in advance what the right threshold is for each use case, every segment, or any feature. When the threshold isn’t right, there’s a good chance it will lead to an overload of unwanted noise that is neither actionable nor important.
There’s no clear workflow and stakeholder alignment.
One of the first challenges companies face when putting ML models into production is finding a way to standardize the process of detecting, dealing with, and resolving model-related cases– especially since these inevitably impact the business. What should the problem resolution workflow look like? Who is responsible for it? Will the same person handle every kind of alert?
When you’ve got a limited ML monitoring solution in place, it generally remains siloed and will be accessible to only a limited set of people–maybe just the data scientist. These solutions are generally restricted when it comes to defining different owners per use case, per workflow, or per issue.
How to combat ML monitoring debt
The first thing to do when your monitoring method falls behind is to ask yourself whether you have the ability to identify problems in real-time—and not after the fact or as a result of something else. Once you can be sure you’re getting alerts when something goes wrong, you’ll be able to stop the debt from piling up even further.
Use case flexibility
Another critical task is to make sure your monitoring tool can give you visibility for multiple use cases and not just one type of data.
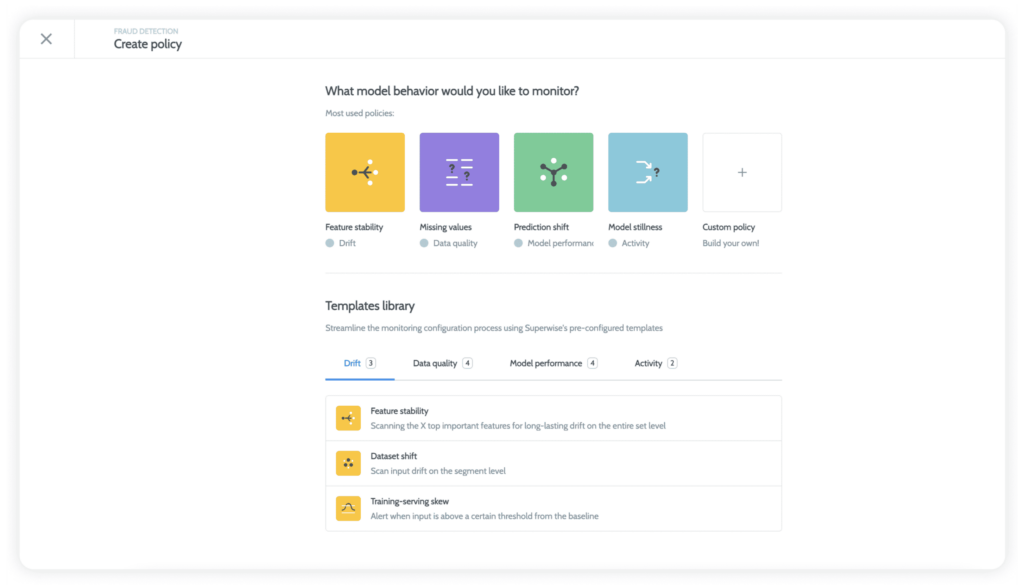
Incidents, not dashboards
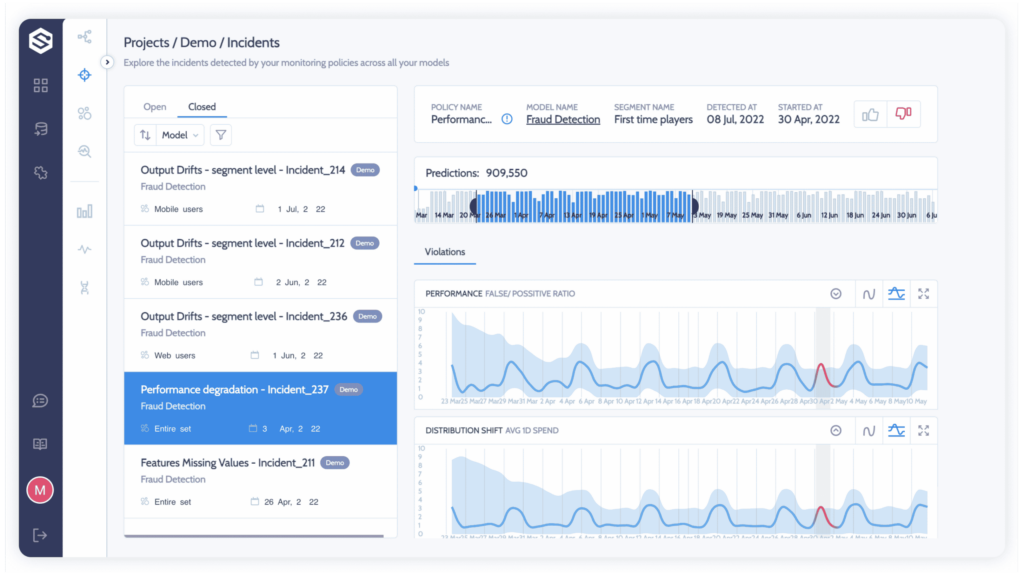
In a state of continuous alert fatigue, scientists and machine learning engineers can’t afford to analyze every issue, and uncovering the root cause is not a straightforward task. Practitioners need to dig into segments and resolutions to find the areas where models are performing worse than they could be or failing outright. With incident management, you can clearly see what went wrong and who was affected. This is a much higher level of abstraction than just looking at anomalies, and it will help you quickly identify and fix problems.
Superwise Incidents help you focus on what matters by automatically grouping issues and correlated events when your model starts to misbehave—generating a root-cause investigation view with precisely what you need to solve the problem at hand. This kind of focused view is essential for quickly identifying and solving problems.
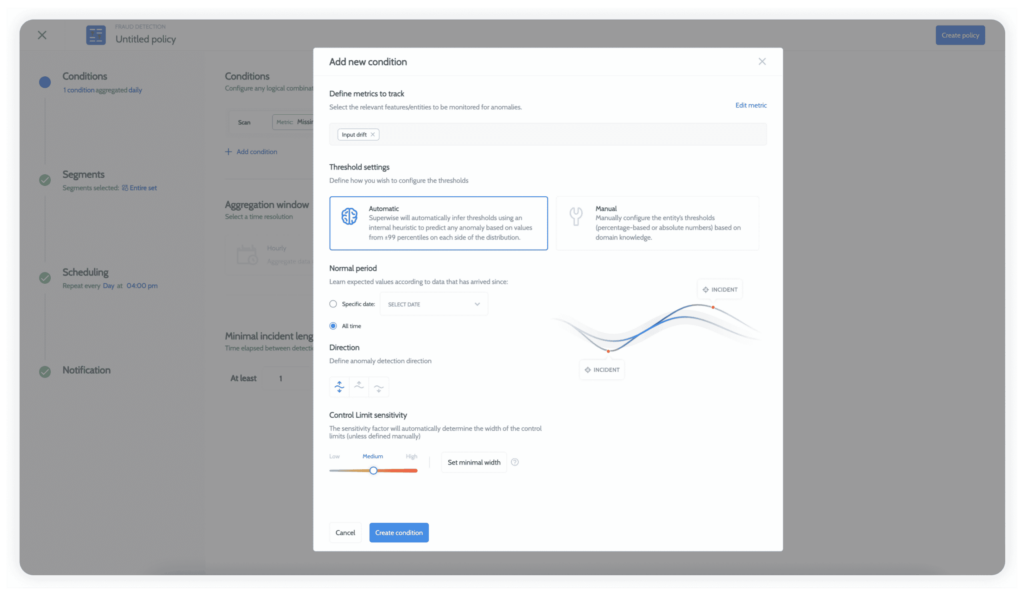
If you’re swamped with alerts, check whether you can customize what you get and when. Make sure you can control the sensitivity of alerts so only those that really offer insight get through, it will be easier for you to identify the problem and how to fix it.
Conclusion
A system that doesn’t have the capabilities described here has the potential to drag you into debt. If your current method of ML monitoring doesn’t have them, this is the time to decide whether you can tweak your current setup or if you need to go all in for a new solution. Making thoughtful decisions about ML monitoring debt often involves learning more about the best practices and tools that are out on the market. This way, you can ensure you have the right features to truly understand how your model is working and when it stops working as planned.
Ready to get started with Superwise projects?
Head over to the Superwise platform and get started with easy, customizable, scalable, and secure model observability for free with our community edition.
Prefer a demo?
Request a demo and our team will show what Superwise can do for your ML and business.