Fundamentals of efficient ML monitoring

Best practices for data science and engineering teams, covering the fundamentals of efficient ML monitoring.
Best practices for data science and engineering teams, covering the fundamentals of efficient ML monitoring.
So how do you go about aligning business and ML to make sure your AI program is not at risk?
Let’s dive into part 2 of safely rolling out models to production, CD, and its online validation strategies – shadow model, A/B testing, multi-armed bandit, etc.
This piece is the first part of a series of articles on production pitfalls and how to rise to the challenge.
–
For any data scientist, the day you roll out your model’s new version to production is a day of mixed feelings. On the one hand, you are releasing a new version that is geared towards yielding better results and making a greater impact; on the other, this is a rather scary and tense time. Your new shiny version may contain flaws that you will only be able to detect after they have had a negative impact.
ML is as complex as orchestrating different instruments
Replacing or publishing a new version to production touches upon the core decision-making logic of your business process. With AI adoption rising, the necessity to automatically publish and update models is becoming a common and frequent task, which makes it a top concern for data science teams.
In this two-part article, we will review what makes the rollout of a new version so sensitive, what precautions are required, and how to leverage monitoring to optimize your Continuous Integration pipeline (Part I) as well as your Continuous Deployment (CD) one to safely achieve your goals.
ML systems are composed of multiple moving and independent parts of software that need to work in tune with each other:
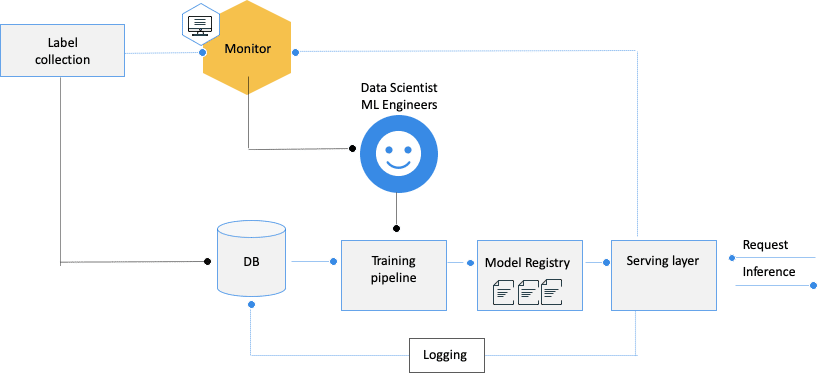
Given this relatively high-level and complex orchestration, many things can get out of sync and lead us to deploy an underperforming model. Some of the most common culprits are:
Most organizations are still manually updating their models. Whether it is the training pipeline or parts of it, such as features selection or the delivery and promotion of the newly created model by the serving layer; doing so manually can lead to errors and unnecessary overheads. To be really efficient: all the processes, from training to monitoring, should be automated to leave less room for error – and more space for efficiency.
As a plurality of stakeholders and experts are involved, there are more handovers and, thus, more room for misunderstandings and integration issues. While the data scientists design the flows, the ML engineers are usually doing the coding – and without being fully aligned, this may result in having models that work well functionally but fail silently, either by using the wrong scaling method or by implementing an incorrect feature engineering logic.
Research mode (batch) is different from production. Developing and empirically researching the optimal training pipeline to yield the best model is done in offline lab environments, with historical datasets, and by simulating hold-out testings. Needless to say, these environments are very different from the production model, for which only parts of the data are actually available. This usually results in containing data leakages or wrong assumptions that lead to bad performance, bias, or problematic code behavior once the model is in production and needs to serve live data streams. For instance, the newly deployed version’s inability to handle new values in a categorical feature while pre-processing it into an embedded vector during the inference phase.
Monitoring ML is more complex than monitoring traditional software – the fact that the entire system is working doesn’t mean it actually does what it should do. Because all the culprits listed above may result in functional errors, and these may be “silent failures”, it is only through robust monitoring that you can detect failures before it is too late and your business is already impacted.
The risks associated with these pitfalls are intrinsically related to the nature of ML operations. Yet, the best practices to overcome them may well come from traditional software engineering and their use of CI/ CD (Continuous Integration/ Continuous Deployment) methodologies. To analyze and recommend best practices for the safe rollout of models, we have used the CI/CD grid to explain which steps should be taken.
CI practices are about frequently testing the codebases of each of the software modules, or unit tests, and the integrity of the different modules working together by using integration/system tests.
Now let’s translate this to the ML orchestra. A new model, or version, should be considered a software artifact that is a part of the general system. As such, the creation of a new model requires a set of unit and integration tests to ensure that the new “candidate” model is valid before it is integrated into the model registry. But in the ML realms, CI is not only about testing and validating code and components but also about testing and validating data, data schemas, and model quality. While the focus of CI is to maintain valid code bases and modules’ artifacts before building new artifacts for each module, the CD process handles the phase of actually deploying the artifacts into production
Here are some of the main best practices for the CI phase that impact the safe rollout of model/new version implementations:
Models are retrained/produced using historical data. For the model to be relevant in production, the training data set should adequately represent the data distribution that currently appears in production. This will avoid selection bias or simply irrelevance. To do so, before even starting the training pipeline, the distribution of the training set should be tested to ensure that it is fit for the task. At this stage, the monitoring solution can be leveraged to provide detailed reports on the distributions of the last production cases, and by using statistical tools such as deequ, this type of data verification constraint can be automatically added to the CI process.
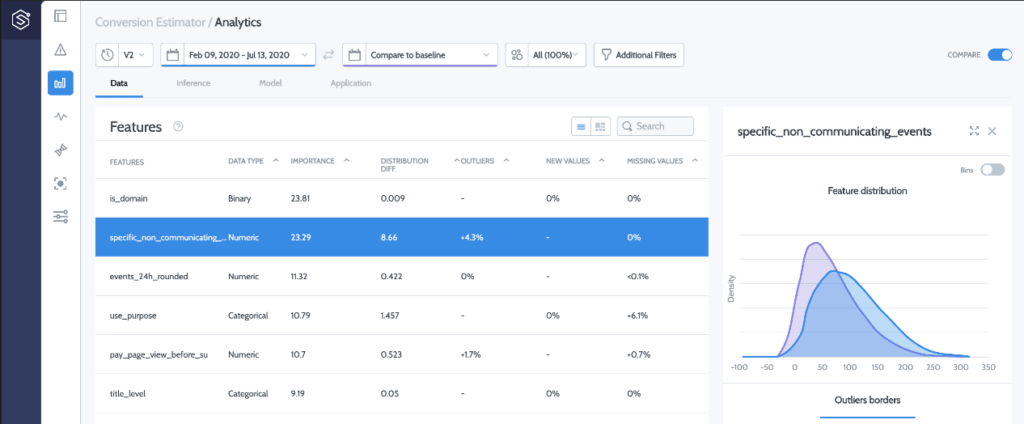
When executing the training pipeline and before submitting the new model as a “candidate” model into the registry, ensure that the new training process undergoes a healthy fit verification.
Even if the training pipeline was automated, it should include a hold-out/cross validation model evaluation step.
Given the selected validation method, one should test that the fitted model convergence doesn’t indicate overfitting, i.e., seeing a reduced loss on the training dataset while it’s increasing on the validation set. The performance should also be above a certain minimal rate – based on a hardcoded threshold, naive model as a baseline, or calculated dynamically by leveraging the monitoring service and extracting the rates of the production model during the used validation set.
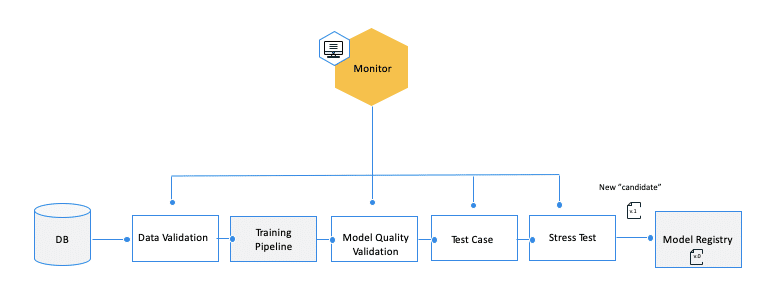
Once the model quality validation phase is completed, one should perform integration tests to see how the serving layer integrates with the new model and whether it successfully serves predictions for specific edge cases. For instance: handling null values in the features that could be nullable, handling new categorical levels in categorical features, working on different lengths of text for text inputs, or even working for different image sizes/resolutions,… Here also, the examples can be synthesized manually or taken from the monitoring solution, whose capabilities include identifying and saving valid inputs with data integrity issues.
Changing the model or changing its pre-processing steps or packages could also impact the model’s operational performance. In many use cases, such as real time-bidding, increasing the latency of the model serving might impact dramatically the business.
Therefore, as a final step in the model CI process, a stress test should be performed to measure the average latency to serve a prediction. Such a metric can be evaluated relative to a business constraint or relative to the current production operational model latency, calculated by the monitoring solution.
Whenever a new model is created, before submitting it to the model “registry”, and as a potential “candidate” to replace the production model, applying these practices to the CI pipelines will help ensure that it works and integrates well with the serving layer.
Yet, while testing these functionalities is necessary, it remains insufficient to safely roll out models and address all the pitfalls listed in this article. For a thorough approach, one should also look at the deployment stage.
Next week, in the second part of this article, we will review what model CD strategies can be used to avoid the risks associated with the rollout of new models/versions, what these strategies require, in which cases they are better fitted, and how they can be achieved using a robust model monitoring service. So stay tuned!
If you have any questions, or feedback, or if you want to brainstorm on the content of this article, please reach out to me on LinkedIn
While it is true to say that AI is everywhere, this is especially accurate when it comes to AI for marketing. Every leading marketing team today knows that machine learning can dramatically help them boost their effectiveness and their impact. Whether it’s to identify and engage users who are most likely to convert, ensure that the lifetime value of customers (LTV) is realized within a short timeframe, or calibrate how much to spend on specific campaigns, the applications are endless when it comes to designing ML-driven razor-sharp marketing programs.
Marketing environments are amongst the most dynamic and complex as they are defined by an (almost) infinite number of data points, a wealth of offerings, and the volatility of customer behavior. As such, marketing applications of AI are amongst the most interesting case studies when it comes to robust AI assurance and monitoring solutions.
In past posts, I referred to the “ownership gap”. In my conversations with prospects and customers, the question of “Who owns your models in production?” is as common as it is thought-provoking. Once models are in production, it’s tough for any organization to determine who is responsible for their health – and it’s especially challenging for marketing use cases. Yet, for most organizations, this “grey area” is left unaddressed; with the data science teams producing the models but without clear definitions of whose role it is to attend to their performance.
There is friction here between the role of the data scientists who create the models and that of the marketing teams who actually use the models. And the friction is not only a conceptual one, rather, it impacts the day-to-day processes of most organizations – organizations that need to empower their marketing teams while reducing the “maintenance and troubleshooting” overheads of their data science teams.
While AI practitioners and organizations are better understanding the need for a monitoring strategy, the matter of the ownership of models in production remains a yawning gap. For marketing use cases, in particular, it seems that the actual predictions are owned by marketing analysts and that they need to have a clear understanding of what drives these predictions and their seasonality: was there a change in the data traffic, or are these results of their own efforts? How dependent are they on the actual feedback from the predictions, which may take days or even weeks, in order to determine how well they are doing?
The success of marketing campaigns lies in their ability to understand their users at an almost intimate level. That is to say, below the surface. In this sense, granularity and an understanding of the statistical significance of specific sub-populations are paramount for marketers. If specific metrics are considered valid for the data science team, they may not necessarily be valid for your marketing teams. Let’s take the example of accuracy. A 75% accuracy rate may be good enough for your overall model. But if this model is only 30% accurate for a specific sub-group of your customers that you’re targeting, then how good is it for your business? And how bad could that be for your next campaign?
As such, it becomes clearer that monitoring the health of your models is not only about ensuring their performance, and it’s not only about looking at the high-level business result metrics. It’s also – and no less importantly – about having the right visibility and the right level of control for both the data science and the business operations teams.
More to the point, timing is of the essence. Very often, the realization that something went wrong with the predictions only comes once the business has already been impacted. Ultimately, this makes the marketing team less enthusiastic about relying on AI predictions which may translate into friction and frustrating, manual exploration, and putting out fires that will leave your data science teams out of breath. In other words, without the right visibility at the right time, your AI program will not have the impact it was designed for.
This is where AI assurance comes into play. It’s the ideal solution to monitor the health of your models while supporting the right set of practices that will help all of your teams gain the right insights at the right time. Whether it’s a bias or a concept drift, your data science teams need to know to optimize their models – and your marketing team wants to know to optimize their campaigns.
At Superwise, we monitor the health of your models in production while alerting you when something goes wrong. We also provide complete visibility as to what’s going on – we do so by creating a single common language across the enterprise so that data science and marketing teams can each benefit:
Do better marketing – More than 10% error reduction in campaign spend
Marketing teams can now independently understand when the predictions they receive are not optimal in a timely manner and gain insights into the data categories that influence the model and the decision-making processes before damage is done. By catching degradations in real-time – whether data or infrastructure changes, drifts, and biases, investment leakage can be reduced. In addition, the ability to analyze data at a low granularity enables teams to track specific behaviors for particular segments and optimize their campaigns.
Do less firefighting – 96% reduction in time to detect and fix anomalies.
With Superwise, data science teams benefit from a thorough understanding of their model’s health with metrics and performance tracking over time and versions and automatic predictions of performance levels to circumvent blindspot periods. The days of waiting for the business to be impacted to have a sense of the health of the models are long gone!
Data science teams can also receive alerts on drifts/biases to enable more proactivity and prevent AI failures: data and concept drifts, biases, performance issues, and correlated events to avoid too much noise. Last but not least, they can derive better retraining strategies with key insights into the real-life behavior of the models.
In this blog, we look at how fraud detection solution vendors can leverage their ML monitoring solutions to boost the efficiency of their fraud and data science teams and deliver better service to their merchants.




